Contents
- OpenStack - A Modular Collection of Cloud Services
- OpenStack Compute (project name: Nova)
- OpenStack Block Storage (project name: Cinder)
- OpenStack Object Storage (project name: Swift)
- OpenStack Dashboard (project name: Horizon)
- OpenStack Identity (project name: Keystone)
- OpenStack Image Service (project name: Glance)
- OpenStack Network Service (project name: Neutron)
- OpenStack Telemetry (project name: Ceilometer)
- OpenStack Orchestration (project name: Heat)
- OpenStack Database as a Service (project name: Trove)
- OpenStack Hadoop as a Service (project name: Sahara)
- OpenStack File Share Service (project name: Manila)
OpenStack - A Modular Collection of Cloud Services¶
The various OpenStack community projects and the services they implement are modular in nature and generally capable of being used independently. They are intended to knit together into a net capability greater than the sum of the individual parts.
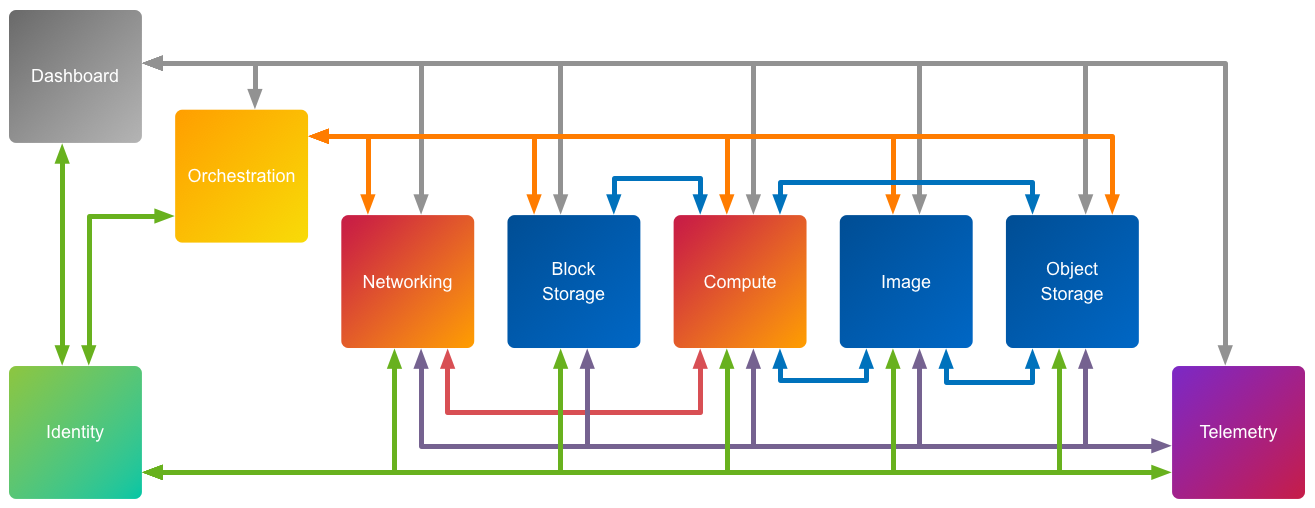
Figure 2.1. OpenStack High Level Architecture
OpenStack Compute (project name: Nova)¶
OpenStack enables enterprises and service providers to offer on-demand computing resources by provisioning and managing large networks of virtual machines. Compute resources are accessible via APIs for developers building cloud applications and through web interfaces for administrators and users. The compute architecture is designed to scale horizontally on standard hardware. OpenStack Compute is architected to avoid inherent proprietary hardware or software requirements and the ability to integrate with existing systems and third-party technologies. It is designed to manage and automate pools of compute resources and can work with widely available virtualization technologies, as well as bare metal and high-performance computing configurations.
OpenStack Block Storage (project name: Cinder)¶
OpenStack Block Storage provides a “block storage as a service” capability. It provides persistent block devices mapped to OpenStack compute instances (which are otherwise assumed to be ephemeral). The block storage system manages the creation, attaching and detaching of the block devices to instances. It also optionally supports instance booting and provides mechanisms for creating Snapshot copies and cloning. While fully integrated with OpenStack Compute and Dashboard, it can also be used independent of OpenStack to provide a standardized abstraction for block storage provisioning.
OpenStack Object Storage (project name: Swift)¶
OpenStack Object Storage provides a fully distributed, scale-out, API-accessible storage platform that can be integrated directly into applications or used for backup, archiving and data retention. Object storage does not present a traditional file system, but rather a distributed storage system for static data such as virtual machine images, photo storage, email storage, backups and archives. The OpenStack Object Storage API (aka Swift API), in a manner somewhat similar to CDMI, proposes an open standard for cloud storage. It can also function as an alternative endpoint for Amazon Web Services S3 and as a CDMI server through the use of add-on components.
OpenStack Dashboard (project name: Horizon)¶
The OpenStack Dashboard provides administrators and users a graphical interface to access, provision and automate cloud-based resources. The extensible design makes it easy to plug in and expose third-party products and services, such as billing, monitoring, and additional management tools. The dashboard can also be made brand specific for service providers and other Enterprises who require customization. The dashboard is one of several ways to interact with OpenStack resources. Developers can automate access or build tools to manage their resources that use the native OpenStack API or the EC2 compatibility API. The dashboard provides users a self-service portal to provision their own resources within the limits set by administrators.
OpenStack Identity (project name: Keystone)¶
OpenStack Identity provides a central directory of users mapped to the OpenStack services they can access. It acts as a common authentication system across the cloud operating system and can integrate with existing backend directory services (for example, LDAP). It supports multiple forms of authentication including standard user name and password credentials, token-based systems and AWS-style logins. Additionally, the catalog provides a list of all of the services deployed in an OpenStack cloud in that can be queried in a single registry. Users and third-party tools can programmatically determine which resources they can access. OpenStack Identity enables:
- Configuration of centralized policies across users and systems
- Creation of users and tenants and define permissions for compute, storage and networking resources through the use of role-based access control (RBAC) features
- Integration with existing directories, allowing for a single source of identity authentication
- As a user, get a list of the services that you can access and make API requests or log into the web dashboard to create resources owned by your account
OpenStack Image Service (project name: Glance)¶
The OpenStack Image Service provides discovery, registration and delivery services for disk and server images. The ability to copy or snapshot a server image and immediately store it away is a powerful capability of the OpenStack cloud operating system. Stored images can be used as a template to get new servers up and running quickly and more consistently if you are provisioning multiple servers than installing a server operating system and individually configuring additional services. It can also be used to store and catalog an unlimited number of backups. The Image Service can store disk and server images in a variety of back-ends, including through NFS and Object Storage. The Image Service API provides a standard REST interface for querying information about disk images and lets clients stream the images to new servers. A multiformat image registry allowing uploads of private and public images in a variety of formats.
OpenStack Network Service (project name: Neutron)¶
OpenStack Networking is a pluggable, scalable and API-driven system for managing networks and IP addresses. Like other aspects of the cloud operating system, it can be used by administrators and users to increase the value of existing data center assets. OpenStack Networking ensures the network is not the bottleneck or limiting factor in a cloud deployment and provides users self-service over their own network configurations. The pluggable backend architecture lets users take advantage of basic commodity gear or advanced networking services from supported vendors. Administrators can take advantage of software-defined networking (SDN) technology like OpenFlow to allow high levels of multi-tenancy and massive scale. OpenStack Networking has an extension framework allowing additional network services, such as intrusion detection systems (IDS), load balancing, firewalls and virtual private networks (VPN) to be deployed and managed.
OpenStack Telemetry (project name: Ceilometer)¶
OpenStack Telemetry provides common infrastructure to collect usage and performance measurements within an OpenStack cloud. Its primary initial targets are monitoring and metering, but the framework is expandable to collect data for other needs. Ceilometer was promoted from incubation status to an integrated component of OpenStack in the Grizzly (April 2013) release.
OpenStack Orchestration (project name: Heat)¶
OpenStack Orchestration implements a service to orchestrate multiple composite cloud applications that use the Amazon Web Services (AWS) CloudFormation template format, through both an OpenStack-native and CloudFormation-compatible API. It is intended, in part, to facilitate movement of workloads from AWS to OpenStack deployments. Heat was promoted from incubation status to an integrated component of OpenStack in the Grizzly (April 2013) release.
OpenStack Database as a Service (project name: Trove)¶
OpenStack Database as a Service allows users to quickly and easily utilize the features of a relational database without the burden of handling complex administrative tasks. Cloud users and database administrators can provision and manage multiple database instances as needed. Initially, the service focuses on providing resource isolation at high performance while automating complex administrative tasks including deployment, configuration, patching, backups, restores, and monitoring. Trove was promoted from incubation status to an integrated component of OpenStack in the Icehouse (April 2014) release.
OpenStack Hadoop as a Service (project name: Sahara)¶
The OpenStack Hadoop as a Service project aims to provide users with simple means to provision a Hadoop cluster by specifying several parameters like Hadoop version, cluster topology, nodes’ hardware details, etc. Sahara was promoted from incubation status to an integrated component of OpenStack in the Icehouse (April 2014) release.
This document is licensed under Apache 2.0 license.